Feature Selection
TOC
Introduction
Feature selection is a technique in machine learning that only choose a subset of all the available features to construct a model. We know that not all features contributes to the prediction equally. For example, to predict a house price, the size of house can be much more important than the address of the house. So feature selection can help to reduce the number of variables, that would reduce computation cost and training time and make the model more parsimonious. The more important thing is that those variables are qualitatively different, so if there is an algorithm or procedure to select only the most contributing attributes, it would be better. This can combat overfitting and help with the ultimate goal of generalization, since the model sees the underlying pattern of the data. That would also possible make the model perform better.
Feature selection is a part of feature engineering (create new variables that make better sense). And it is part of the process of understanding your data qualitatively. So make sure you run multiple feature selecting algorithms then use logics and domain knowledge to evaluate each feature thoroughly before deciding to drop or to add features. Another thing to note is that some feature selection algorithms consider features individually. They cannot take into account feature interactions. That might be the broader task of feature engineering (to combine and make meaningful variables from the feature set).
Automatically, there are ways to do feature selection:
- Filter method: This is to score the relevance of each feature to the target variable, making use of statistical measures such as Chi-Squared test, information gain, correlation coefficients.
- Wrapper method: Why not use a model to predict the importance of the features? The search can be an exhaustive algorithm, or heuristics such as forward selection, backward elemination, recursive feature eliminiation, genetic algorithm.
- Embedded method: The model to select features is embeded into the final model construction process, using models such as LASSO, elastic net, decision tree, random forest. This method can be more efficient than the above.
Filter method
Chi squared test
This statistical test is to evaluate the likelihood of correlation between variables using their distribution. Intuitively, we start with the simple assumption that all variables appear equally in frequency, i.e. they are independent. If the observed frequency is different from the expected frequency, they are actually dependent.
Let’s say we have 2 categorical variables X and Y. Attribute X has two values X1 and X2, attribute Y has two values Y1 and Y2 likewise. To see whether X and Y are dependent, we aggregate their dependent frequency:
| X1 | X2 | Total | |
|---|---|---|---|
| Y1 | 120 | 80 | 200 |
| Y2 | 130 | 60 | 190 |
| Total | 250 | 140 | 390 |
We interpret the above table as follows: there are 100 observations that has both attributes X1 and Y1. Then we define the hypothesis H0 to be no association between X and Y, H1 to be there is association between X and Y.
In step 2, we calculate the expected frequency for each cell: \(Expected Frequency = \frac{Row total * Column total}{Total}\). For example, the expected observations in the first cell is \((X1,Y1)=\frac{250*200}{390} = 128\). So we expect to see 128 observations that have the combination (X1,Y1). Here is the expected frequencies:
| X1 | X2 | Total | |
|---|---|---|---|
| Y1 | 128 | 71 | 200 |
| Y2 | 121 | 68 | 190 |
| Total | 250 | 140 | 390 |
Then we calculate the difference between the expected and the observed frequencies: \(\frac{(observed - expected)^2}{expected}\)
| X1 | X2 | Total | |
|---|---|---|---|
| Y1 | 0.5 | 1.1 | 200 |
| Y2 | 0.7 | 0.9 | 190 |
| Total | 250 | 140 | 390 |
The test statistics chi squared would be the sum of all those differences: 0.5 + 1.1 + 0.7 + 0.9 = 3.2. Now we calculate the degree of freedom of this table: \((rows - 1) * (columns - 1) = (2-1) * (2-1)=1\)
With 1 degree of freedom, choose alpha to be 0.05, check this table:
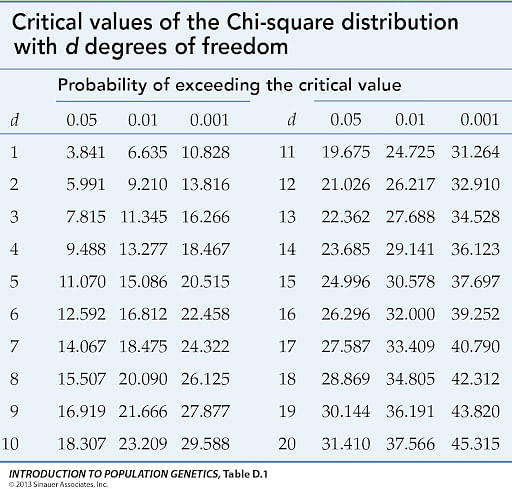
We have the critical value to be 3.841 which is bigger than our chi squared statistics for this dataset. We cannot reject the null hypothesis that there is no link between X and Y. Which we can carefully conclude that there is no link between X and Y.
Usually we use the Chi squared test for category variables. For example, movie genres can have one of these values: action, comedy, thriller, children. However, we can apply the Chi squared test for numerical values too, but we need to bin the data first. Binning a continuous variable is also called bucketting: we divide the range of the variable into smaller intervals making up that range. For example, we divide [0,10] into 3 buckets: [0,3], (3,6], and (6,10]. This gives us something like three categories to work with. The only thing is that when you do this, consider that we lose some information grouping data into buckets. Also, the Chi square test is for frequencies so they are in nature all non negative values. If you have negative values in your dataset, a way to remedy is to turn them into zero.
Code example
In this example, we would look into the home credit default risk dataset, which we can use to predict the unability to pay back the loan. In this case, we would only demonstrate the chi squared test to select the most relevant features for the target variable. There are 1166 features in which 16 are categorical variables. We fill in the missing values with most frequent for categorical variables and mean for numerical variables. We also turn negative values into 0. We would then select the top 8 categorical variables then we select the top 800 numerical variables. The binning of numerical variables would be done automatically by sklearn.
import pandas as pd
import numpy as np
np.set_printoptions(suppress=True)
train = pd.read_csv('home-credit-manual-engineered-features/train_previous_raw.csv', nrows = 1000)
test = pd.read_csv('home-credit-manual-engineered-features/test_previous_raw.csv', nrows = 1000)
train.head()
| SK_ID_CURR | TARGET | NAME_CONTRACT_TYPE | CODE_GENDER | FLAG_OWN_CAR | FLAG_OWN_REALTY | CNT_CHILDREN | AMT_INCOME_TOTAL | AMT_CREDIT | AMT_ANNUITY | ... | client_installments_AMT_PAYMENT_min_sum | client_installments_AMT_PAYMENT_sum_mean | client_installments_AMT_PAYMENT_sum_max | client_installments_AMT_PAYMENT_sum_min | client_installments_AMT_PAYMENT_sum_sum | client_installments_counts_mean | client_installments_counts_max | client_installments_counts_min | client_installments_counts_sum | client_counts | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 100002 | 1 | Cash loans | M | N | Y | 0 | 202500.0 | 406597.5 | 24700.5 | ... | 175783.725 | 219625.695000 | 219625.695 | 219625.695 | 4.172888e+06 | 19.000000 | 19.0 | 19.0 | 361.0 | 19.0 |
| 1 | 100003 | 0 | Cash loans | F | N | N | 0 | 270000.0 | 1293502.5 | 35698.5 | ... | 1154108.295 | 453952.220400 | 1150977.330 | 80773.380 | 1.134881e+07 | 9.160000 | 12.0 | 6.0 | 229.0 | 25.0 |
| 2 | 100004 | 0 | Revolving loans | M | Y | Y | 0 | 67500.0 | 135000.0 | 6750.0 | ... | 16071.750 | 21288.465000 | 21288.465 | 21288.465 | 6.386539e+04 | 3.000000 | 3.0 | 3.0 | 9.0 | 3.0 |
| 3 | 100006 | 0 | Cash loans | F | N | Y | 0 | 135000.0 | 312682.5 | 29686.5 | ... | 994476.690 | 232499.719688 | 691786.890 | 25091.325 | 3.719996e+06 | 7.875000 | 10.0 | 1.0 | 126.0 | 16.0 |
| 4 | 100007 | 0 | Cash loans | M | N | Y | 0 | 121500.0 | 513000.0 | 21865.5 | ... | 483756.390 | 172669.901591 | 280199.700 | 18330.390 | 1.139621e+07 | 13.606061 | 17.0 | 10.0 | 898.0 | 66.0 |
5 rows × 1166 columns
y_train = train['TARGET']
train = train.drop(['TARGET'], axis=1)
y_train = y_train.to_frame()
y_train
| TARGET | |
|---|---|
| 0 | 1 |
| 1 | 0 |
| 2 | 0 |
| 3 | 0 |
| 4 | 0 |
| ... | ... |
| 995 | 0 |
| 996 | 0 |
| 997 | 0 |
| 998 | 0 |
| 999 | 0 |
1000 rows × 1 columns
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
categoricals = ['object']
X_train = train.select_dtypes(include=categoricals)
columns = X_train.columns
from sklearn.impute import SimpleImputer
import numpy as np
imputer = SimpleImputer(missing_values=np.nan, strategy='most_frequent')
imputer = imputer.fit(X_train)
X_train = imputer.transform(X_train)
X_train = pd.DataFrame(data=X_train, columns=columns)
from sklearn.preprocessing import LabelEncoder
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
X_train = X_train.apply(LabelEncoder().fit_transform)
chi2_selector = SelectKBest(chi2, k=3) # Select top 5 features
X_train_kbest = chi2_selector.fit_transform(X_train, y_train)
# To get the selected feature names
selected_features = [feature for feature, mask in zip(X_train.columns, chi2_selector.get_support()) if mask]
print(selected_features)
['client_credit_SK_ID_CURR_sum_sum', 'client_credit_AMT_CREDIT_LIMIT_ACTUAL_sum_sum', 'client_credit_AMT_TOTAL_RECEIVABLE_sum_sum']
X_train = train.select_dtypes(include=numerics)
columns = X_train.columns
from sklearn.impute import SimpleImputer
import numpy as np
imputer = SimpleImputer(missing_values=np.nan, strategy='most_frequent')
imputer = imputer.fit(X_train)
X_train = imputer.transform(X_train)
X_train = pd.DataFrame(data=X_train, columns=columns)
X_train[X_train < 0] = 0
chi2_selector = SelectKBest(chi2, k=800) # Select top 5 features
X_train_kbest = chi2_selector.fit_transform(X_train, y_train)
# To get the selected feature names
selected_features = [feature for feature, mask in zip(X_train.columns, chi2_selector.get_support()) if mask]
print(selected_features)
['SK_ID_CURR', 'CNT_CHILDREN', 'AMT_INCOME_TOTAL', 'AMT_CREDIT', 'AMT_ANNUITY', 'AMT_GOODS_PRICE', 'DAYS_EMPLOYED', 'OWN_CAR_AGE', 'FLAG_WORK_PHONE', 'FLAG_PHONE', 'REGION_RATING_CLIENT', 'REGION_RATING_CLIENT_W_CITY', 'HOUR_APPR_PROCESS_START', 'REG_REGION_NOT_LIVE_REGION', 'REG_REGION_NOT_WORK_REGION', 'LIVE_REGION_NOT_WORK_REGION', 'REG_CITY_NOT_LIVE_CITY', 'REG_CITY_NOT_WORK_CITY', 'LIVE_CITY_NOT_WORK_CITY', 'EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'COMMONAREA_AVG', 'LANDAREA_AVG', 'NONLIVINGAREA_AVG', 'COMMONAREA_MODE', 'LANDAREA_MODE', 'NONLIVINGAREA_MODE', 'COMMONAREA_MEDI', 'LANDAREA_MEDI', 'NONLIVINGAREA_MEDI', 'OBS_30_CNT_SOCIAL_CIRCLE', 'DEF_30_CNT_SOCIAL_CIRCLE', 'OBS_60_CNT_SOCIAL_CIRCLE', 'DEF_60_CNT_SOCIAL_CIRCLE', 'FLAG_DOCUMENT_3', 'FLAG_DOCUMENT_5', 'FLAG_DOCUMENT_9', 'FLAG_DOCUMENT_11', 'FLAG_DOCUMENT_13', 'FLAG_DOCUMENT_14', 'FLAG_DOCUMENT_16', 'FLAG_DOCUMENT_18', 'AMT_REQ_CREDIT_BUREAU_HOUR', 'AMT_REQ_CREDIT_BUREAU_DAY', 'AMT_REQ_CREDIT_BUREAU_WEEK', 'AMT_REQ_CREDIT_BUREAU_MON', 'AMT_REQ_CREDIT_BUREAU_QRT', 'AMT_REQ_CREDIT_BUREAU_YEAR', 'previous_loans_NAME_CONTRACT_TYPE_Cash loans_count', 'previous_loans_NAME_CONTRACT_TYPE_Cash loans_count_norm', 'previous_loans_NAME_CONTRACT_TYPE_Consumer loans_count', 'previous_loans_NAME_CONTRACT_TYPE_XNA_count', 'previous_loans_WEEKDAY_APPR_PROCESS_START_FRIDAY_count', 'previous_loans_WEEKDAY_APPR_PROCESS_START_FRIDAY_count_norm', 'previous_loans_WEEKDAY_APPR_PROCESS_START_MONDAY_count', 'previous_loans_WEEKDAY_APPR_PROCESS_START_SATURDAY_count', 'previous_loans_WEEKDAY_APPR_PROCESS_START_SUNDAY_count', 'previous_loans_WEEKDAY_APPR_PROCESS_START_SUNDAY_count_norm', 'previous_loans_WEEKDAY_APPR_PROCESS_START_THURSDAY_count', 'previous_loans_WEEKDAY_APPR_PROCESS_START_THURSDAY_count_norm', 'previous_loans_WEEKDAY_APPR_PROCESS_START_TUESDAY_count', 'previous_loans_WEEKDAY_APPR_PROCESS_START_TUESDAY_count_norm', 'previous_loans_WEEKDAY_APPR_PROCESS_START_WEDNESDAY_count', 'previous_loans_WEEKDAY_APPR_PROCESS_START_WEDNESDAY_count_norm', 'previous_loans_FLAG_LAST_APPL_PER_CONTRACT_N_count', 'previous_loans_FLAG_LAST_APPL_PER_CONTRACT_N_count_norm', 'previous_loans_FLAG_LAST_APPL_PER_CONTRACT_Y_count', 'previous_loans_NAME_CASH_LOAN_PURPOSE_Building a house or an annex_count', 'previous_loans_NAME_CASH_LOAN_PURPOSE_Buying a holiday home / land_count', 'previous_loans_NAME_CASH_LOAN_PURPOSE_Buying a new car_count', 'previous_loans_NAME_CASH_LOAN_PURPOSE_Buying a new car_count_norm', 'previous_loans_NAME_CASH_LOAN_PURPOSE_Buying a used car_count', 'previous_loans_NAME_CASH_LOAN_PURPOSE_Buying a used car_count_norm', 'previous_loans_NAME_CASH_LOAN_PURPOSE_Car repairs_count', 'previous_loans_NAME_CASH_LOAN_PURPOSE_Car repairs_count_norm', 'previous_loans_NAME_CASH_LOAN_PURPOSE_Everyday expenses_count', 'previous_loans_NAME_CASH_LOAN_PURPOSE_Everyday expenses_count_norm', 'previous_loans_NAME_CASH_LOAN_PURPOSE_Medicine_count', 'previous_loans_NAME_CASH_LOAN_PURPOSE_Other_count', 'previous_loans_NAME_CASH_LOAN_PURPOSE_Payments on other loans_count', 'previous_loans_NAME_CASH_LOAN_PURPOSE_Payments on other loans_count_norm', 'previous_loans_NAME_CASH_LOAN_PURPOSE_Purchase of electronic equipment_count', 'previous_loans_NAME_CASH_LOAN_PURPOSE_Purchase of electronic equipment_count_norm', 'previous_loans_NAME_CASH_LOAN_PURPOSE_Repairs_count_norm', 'previous_loans_NAME_CASH_LOAN_PURPOSE_Urgent needs_count', 'previous_loans_NAME_CASH_LOAN_PURPOSE_Wedding / gift / holiday_count', 'previous_loans_NAME_CASH_LOAN_PURPOSE_XAP_count', 'previous_loans_NAME_CASH_LOAN_PURPOSE_XAP_count_norm', 'previous_loans_NAME_CASH_LOAN_PURPOSE_XNA_count', 'previous_loans_NAME_CASH_LOAN_PURPOSE_XNA_count_norm', 'previous_loans_NAME_CONTRACT_STATUS_Approved_count', 'previous_loans_NAME_CONTRACT_STATUS_Approved_count_norm', 'previous_loans_NAME_CONTRACT_STATUS_Canceled_count', 'previous_loans_NAME_CONTRACT_STATUS_Canceled_count_norm', 'previous_loans_NAME_CONTRACT_STATUS_Refused_count', 'previous_loans_NAME_CONTRACT_STATUS_Refused_count_norm', 'previous_loans_NAME_CONTRACT_STATUS_Unused offer_count', 'previous_loans_NAME_CONTRACT_STATUS_Unused offer_count_norm', 'previous_loans_NAME_PAYMENT_TYPE_Cash through the bank_count', 'previous_loans_NAME_PAYMENT_TYPE_Cashless from the account of the employer_count', 'previous_loans_NAME_PAYMENT_TYPE_Non-cash from your account_count', 'previous_loans_NAME_PAYMENT_TYPE_Non-cash from your account_count_norm', 'previous_loans_NAME_PAYMENT_TYPE_XNA_count', 'previous_loans_CODE_REJECT_REASON_CLIENT_count', 'previous_loans_CODE_REJECT_REASON_CLIENT_count_norm', 'previous_loans_CODE_REJECT_REASON_HC_count', 'previous_loans_CODE_REJECT_REASON_HC_count_norm', 'previous_loans_CODE_REJECT_REASON_LIMIT_count_norm', 'previous_loans_CODE_REJECT_REASON_SCO_count', 'previous_loans_CODE_REJECT_REASON_SCO_count_norm', 'previous_loans_CODE_REJECT_REASON_SCOFR_count', 'previous_loans_CODE_REJECT_REASON_SCOFR_count_norm', 'previous_loans_CODE_REJECT_REASON_SYSTEM_count', 'previous_loans_CODE_REJECT_REASON_VERIF_count', 'previous_loans_CODE_REJECT_REASON_VERIF_count_norm', 'previous_loans_CODE_REJECT_REASON_XAP_count', 'previous_loans_CODE_REJECT_REASON_XAP_count_norm', 'previous_loans_CODE_REJECT_REASON_XNA_count', 'previous_loans_NAME_TYPE_SUITE_Children_count', 'previous_loans_NAME_TYPE_SUITE_Children_count_norm', 'previous_loans_NAME_TYPE_SUITE_Group of people_count', 'previous_loans_NAME_TYPE_SUITE_Group of people_count_norm', 'previous_loans_NAME_TYPE_SUITE_Other_A_count', 'previous_loans_NAME_TYPE_SUITE_Other_A_count_norm', 'previous_loans_NAME_TYPE_SUITE_Other_B_count', 'previous_loans_NAME_TYPE_SUITE_Other_B_count_norm', 'previous_loans_NAME_TYPE_SUITE_Spouse, partner_count', 'previous_loans_NAME_TYPE_SUITE_Spouse, partner_count_norm', 'previous_loans_NAME_TYPE_SUITE_Unaccompanied_count', 'previous_loans_NAME_TYPE_SUITE_Unaccompanied_count_norm', 'previous_loans_NAME_CLIENT_TYPE_New_count', 'previous_loans_NAME_CLIENT_TYPE_New_count_norm', 'previous_loans_NAME_CLIENT_TYPE_Repeater_count', 'previous_loans_NAME_CLIENT_TYPE_Repeater_count_norm', 'previous_loans_NAME_CLIENT_TYPE_XNA_count', 'previous_loans_NAME_GOODS_CATEGORY_Audio/Video_count', 'previous_loans_NAME_GOODS_CATEGORY_Auto Accessories_count', 'previous_loans_NAME_GOODS_CATEGORY_Clothing and Accessories_count', 'previous_loans_NAME_GOODS_CATEGORY_Clothing and Accessories_count_norm', 'previous_loans_NAME_GOODS_CATEGORY_Computers_count', 'previous_loans_NAME_GOODS_CATEGORY_Computers_count_norm', 'previous_loans_NAME_GOODS_CATEGORY_Construction Materials_count', 'previous_loans_NAME_GOODS_CATEGORY_Construction Materials_count_norm', 'previous_loans_NAME_GOODS_CATEGORY_Consumer Electronics_count', 'previous_loans_NAME_GOODS_CATEGORY_Consumer Electronics_count_norm', 'previous_loans_NAME_GOODS_CATEGORY_Furniture_count', 'previous_loans_NAME_GOODS_CATEGORY_Furniture_count_norm', 'previous_loans_NAME_GOODS_CATEGORY_Gardening_count', 'previous_loans_NAME_GOODS_CATEGORY_Homewares_count_norm', 'previous_loans_NAME_GOODS_CATEGORY_Jewelry_count', 'previous_loans_NAME_GOODS_CATEGORY_Jewelry_count_norm', 'previous_loans_NAME_GOODS_CATEGORY_Medical Supplies_count', 'previous_loans_NAME_GOODS_CATEGORY_Medical Supplies_count_norm', 'previous_loans_NAME_GOODS_CATEGORY_Medicine_count', 'previous_loans_NAME_GOODS_CATEGORY_Medicine_count_norm', 'previous_loans_NAME_GOODS_CATEGORY_Mobile_count', 'previous_loans_NAME_GOODS_CATEGORY_Mobile_count_norm', 'previous_loans_NAME_GOODS_CATEGORY_Office Appliances_count', 'previous_loans_NAME_GOODS_CATEGORY_Office Appliances_count_norm', 'previous_loans_NAME_GOODS_CATEGORY_Other_count', 'previous_loans_NAME_GOODS_CATEGORY_Other_count_norm', 'previous_loans_NAME_GOODS_CATEGORY_Photo / Cinema Equipment_count', 'previous_loans_NAME_GOODS_CATEGORY_Sport and Leisure_count', 'previous_loans_NAME_GOODS_CATEGORY_Tourism_count', 'previous_loans_NAME_GOODS_CATEGORY_Vehicles_count', 'previous_loans_NAME_GOODS_CATEGORY_Vehicles_count_norm', 'previous_loans_NAME_GOODS_CATEGORY_Weapon_count', 'previous_loans_NAME_PORTFOLIO_Cards_count', 'previous_loans_NAME_PORTFOLIO_Cars_count', 'previous_loans_NAME_PORTFOLIO_Cars_count_norm', 'previous_loans_NAME_PORTFOLIO_Cash_count', 'previous_loans_NAME_PORTFOLIO_POS_count', 'previous_loans_NAME_PORTFOLIO_XNA_count', 'previous_loans_NAME_PRODUCT_TYPE_XNA_count', 'previous_loans_NAME_PRODUCT_TYPE_walk-in_count', 'previous_loans_NAME_PRODUCT_TYPE_walk-in_count_norm', 'previous_loans_NAME_PRODUCT_TYPE_x-sell_count', 'previous_loans_NAME_PRODUCT_TYPE_x-sell_count_norm', 'previous_loans_CHANNEL_TYPE_AP+ (Cash loan)_count', 'previous_loans_CHANNEL_TYPE_AP+ (Cash loan)_count_norm', 'previous_loans_CHANNEL_TYPE_Car dealer_count', 'previous_loans_CHANNEL_TYPE_Car dealer_count_norm', 'previous_loans_CHANNEL_TYPE_Channel of corporate sales_count', 'previous_loans_CHANNEL_TYPE_Channel of corporate sales_count_norm', 'previous_loans_CHANNEL_TYPE_Contact center_count', 'previous_loans_CHANNEL_TYPE_Contact center_count_norm', 'previous_loans_CHANNEL_TYPE_Country-wide_count', 'previous_loans_CHANNEL_TYPE_Credit and cash offices_count', 'previous_loans_CHANNEL_TYPE_Credit and cash offices_count_norm', 'previous_loans_CHANNEL_TYPE_Regional / Local_count', 'previous_loans_CHANNEL_TYPE_Regional / Local_count_norm', 'previous_loans_CHANNEL_TYPE_Stone_count', 'previous_loans_NAME_SELLER_INDUSTRY_Auto technology_count', 'previous_loans_NAME_SELLER_INDUSTRY_Auto technology_count_norm', 'previous_loans_NAME_SELLER_INDUSTRY_Clothing_count', 'previous_loans_NAME_SELLER_INDUSTRY_Clothing_count_norm', 'previous_loans_NAME_SELLER_INDUSTRY_Connectivity_count_norm', 'previous_loans_NAME_SELLER_INDUSTRY_Consumer electronics_count', 'previous_loans_NAME_SELLER_INDUSTRY_Consumer electronics_count_norm', 'previous_loans_NAME_SELLER_INDUSTRY_Furniture_count', 'previous_loans_NAME_SELLER_INDUSTRY_Furniture_count_norm', 'previous_loans_NAME_SELLER_INDUSTRY_Industry_count', 'previous_loans_NAME_SELLER_INDUSTRY_Industry_count_norm', 'previous_loans_NAME_SELLER_INDUSTRY_Jewelry_count', 'previous_loans_NAME_SELLER_INDUSTRY_Jewelry_count_norm', 'previous_loans_NAME_SELLER_INDUSTRY_Tourism_count', 'previous_loans_NAME_SELLER_INDUSTRY_XNA_count', 'previous_loans_NAME_YIELD_GROUP_XNA_count', 'previous_loans_NAME_YIELD_GROUP_high_count', 'previous_loans_NAME_YIELD_GROUP_high_count_norm', 'previous_loans_NAME_YIELD_GROUP_low_action_count', 'previous_loans_NAME_YIELD_GROUP_low_action_count_norm', 'previous_loans_NAME_YIELD_GROUP_low_normal_count', 'previous_loans_NAME_YIELD_GROUP_middle_count', 'previous_loans_NAME_YIELD_GROUP_middle_count_norm', 'previous_loans_PRODUCT_COMBINATION_Card Street_count', 'previous_loans_PRODUCT_COMBINATION_Card Street_count_norm', 'previous_loans_PRODUCT_COMBINATION_Card X-Sell_count', 'previous_loans_PRODUCT_COMBINATION_Card X-Sell_count_norm', 'previous_loans_PRODUCT_COMBINATION_Cash_count', 'previous_loans_PRODUCT_COMBINATION_Cash_count_norm', 'previous_loans_PRODUCT_COMBINATION_Cash Street: high_count_norm', 'previous_loans_PRODUCT_COMBINATION_Cash Street: low_count', 'previous_loans_PRODUCT_COMBINATION_Cash Street: low_count_norm', 'previous_loans_PRODUCT_COMBINATION_Cash Street: middle_count', 'previous_loans_PRODUCT_COMBINATION_Cash X-Sell: high_count', 'previous_loans_PRODUCT_COMBINATION_Cash X-Sell: low_count', 'previous_loans_PRODUCT_COMBINATION_Cash X-Sell: low_count_norm', 'previous_loans_PRODUCT_COMBINATION_Cash X-Sell: middle_count', 'previous_loans_PRODUCT_COMBINATION_Cash X-Sell: middle_count_norm', 'previous_loans_PRODUCT_COMBINATION_POS household with interest_count', 'previous_loans_PRODUCT_COMBINATION_POS household with interest_count_norm', 'previous_loans_PRODUCT_COMBINATION_POS household without interest_count', 'previous_loans_PRODUCT_COMBINATION_POS household without interest_count_norm', 'previous_loans_PRODUCT_COMBINATION_POS industry with interest_count', 'previous_loans_PRODUCT_COMBINATION_POS industry with interest_count_norm', 'previous_loans_PRODUCT_COMBINATION_POS industry without interest_count', 'previous_loans_PRODUCT_COMBINATION_POS industry without interest_count_norm', 'previous_loans_PRODUCT_COMBINATION_POS mobile with interest_count', 'previous_loans_PRODUCT_COMBINATION_POS mobile with interest_count_norm', 'previous_loans_PRODUCT_COMBINATION_POS mobile without interest_count_norm', 'previous_loans_PRODUCT_COMBINATION_POS other with interest_count', 'previous_loans_PRODUCT_COMBINATION_POS other with interest_count_norm', 'previous_loans_PRODUCT_COMBINATION_POS others without interest_count', 'previous_loans_PRODUCT_COMBINATION_POS others without interest_count_norm', 'previous_loans_AMT_ANNUITY_mean', 'previous_loans_AMT_ANNUITY_max', 'previous_loans_AMT_ANNUITY_min', 'previous_loans_AMT_ANNUITY_sum', 'previous_loans_AMT_APPLICATION_mean', 'previous_loans_AMT_APPLICATION_max', 'previous_loans_AMT_APPLICATION_min', 'previous_loans_AMT_APPLICATION_sum', 'previous_loans_AMT_CREDIT_mean', 'previous_loans_AMT_CREDIT_max', 'previous_loans_AMT_CREDIT_min', 'previous_loans_AMT_CREDIT_sum', 'previous_loans_AMT_DOWN_PAYMENT_mean', 'previous_loans_AMT_DOWN_PAYMENT_max', 'previous_loans_AMT_DOWN_PAYMENT_min', 'previous_loans_AMT_DOWN_PAYMENT_sum', 'previous_loans_AMT_GOODS_PRICE_mean', 'previous_loans_AMT_GOODS_PRICE_max', 'previous_loans_AMT_GOODS_PRICE_min', 'previous_loans_AMT_GOODS_PRICE_sum', 'previous_loans_HOUR_APPR_PROCESS_START_mean', 'previous_loans_HOUR_APPR_PROCESS_START_max', 'previous_loans_HOUR_APPR_PROCESS_START_min', 'previous_loans_HOUR_APPR_PROCESS_START_sum', 'previous_loans_NFLAG_LAST_APPL_IN_DAY_sum', 'previous_loans_RATE_DOWN_PAYMENT_mean', 'previous_loans_RATE_DOWN_PAYMENT_max', 'previous_loans_RATE_DOWN_PAYMENT_sum', 'previous_loans_SELLERPLACE_AREA_mean', 'previous_loans_SELLERPLACE_AREA_max', 'previous_loans_SELLERPLACE_AREA_min', 'previous_loans_SELLERPLACE_AREA_sum', 'previous_loans_CNT_PAYMENT_mean', 'previous_loans_CNT_PAYMENT_max', 'previous_loans_CNT_PAYMENT_min', 'previous_loans_CNT_PAYMENT_sum', 'previous_loans_DAYS_FIRST_DRAWING_mean', 'previous_loans_DAYS_FIRST_DRAWING_max', 'previous_loans_DAYS_FIRST_DRAWING_min', 'previous_loans_DAYS_FIRST_DRAWING_sum', 'previous_loans_DAYS_FIRST_DUE_mean', 'previous_loans_DAYS_FIRST_DUE_max', 'previous_loans_DAYS_FIRST_DUE_min', 'previous_loans_DAYS_FIRST_DUE_sum', 'previous_loans_DAYS_LAST_DUE_1ST_VERSION_mean', 'previous_loans_DAYS_LAST_DUE_1ST_VERSION_max', 'previous_loans_DAYS_LAST_DUE_1ST_VERSION_min', 'previous_loans_DAYS_LAST_DUE_1ST_VERSION_sum', 'previous_loans_DAYS_LAST_DUE_mean', 'previous_loans_DAYS_LAST_DUE_max', 'previous_loans_DAYS_LAST_DUE_min', 'previous_loans_DAYS_LAST_DUE_sum', 'previous_loans_DAYS_TERMINATION_mean', 'previous_loans_DAYS_TERMINATION_max', 'previous_loans_DAYS_TERMINATION_min', 'previous_loans_DAYS_TERMINATION_sum', 'previous_loans_NFLAG_INSURED_ON_APPROVAL_mean', 'previous_loans_NFLAG_INSURED_ON_APPROVAL_min', 'previous_loans_NFLAG_INSURED_ON_APPROVAL_sum', 'previous_loans_counts', 'client_cash_NAME_CONTRACT_STATUS_Active_count_mean', 'client_cash_NAME_CONTRACT_STATUS_Active_count_sum', 'client_cash_NAME_CONTRACT_STATUS_Active_count_norm_sum', 'client_cash_NAME_CONTRACT_STATUS_Approved_count_min', 'client_cash_NAME_CONTRACT_STATUS_Approved_count_sum', 'client_cash_NAME_CONTRACT_STATUS_Completed_count_mean', 'client_cash_NAME_CONTRACT_STATUS_Completed_count_max', 'client_cash_NAME_CONTRACT_STATUS_Completed_count_min', 'client_cash_NAME_CONTRACT_STATUS_Completed_count_sum', 'client_cash_NAME_CONTRACT_STATUS_Completed_count_norm_mean', 'client_cash_NAME_CONTRACT_STATUS_Completed_count_norm_max', 'client_cash_NAME_CONTRACT_STATUS_Completed_count_norm_min', 'client_cash_NAME_CONTRACT_STATUS_Completed_count_norm_sum', 'client_cash_NAME_CONTRACT_STATUS_Returned to the store_count_mean', 'client_cash_NAME_CONTRACT_STATUS_Returned to the store_count_min', 'client_cash_NAME_CONTRACT_STATUS_Returned to the store_count_sum', 'client_cash_NAME_CONTRACT_STATUS_Returned to the store_count_norm_max', 'client_cash_NAME_CONTRACT_STATUS_Signed_count_mean', 'client_cash_NAME_CONTRACT_STATUS_Signed_count_max', 'client_cash_NAME_CONTRACT_STATUS_Signed_count_min', 'client_cash_NAME_CONTRACT_STATUS_Signed_count_sum', 'client_cash_NAME_CONTRACT_STATUS_Signed_count_norm_min', 'client_cash_SK_ID_CURR_mean_sum', 'client_cash_SK_ID_CURR_max_sum', 'client_cash_SK_ID_CURR_min_sum', 'client_cash_SK_ID_CURR_sum_mean', 'client_cash_SK_ID_CURR_sum_max', 'client_cash_SK_ID_CURR_sum_min', 'client_cash_SK_ID_CURR_sum_sum', 'client_cash_CNT_INSTALMENT_mean_mean', 'client_cash_CNT_INSTALMENT_mean_max', 'client_cash_CNT_INSTALMENT_mean_min', 'client_cash_CNT_INSTALMENT_mean_sum', 'client_cash_CNT_INSTALMENT_max_mean', 'client_cash_CNT_INSTALMENT_max_max', 'client_cash_CNT_INSTALMENT_max_min', 'client_cash_CNT_INSTALMENT_max_sum', 'client_cash_CNT_INSTALMENT_min_mean', 'client_cash_CNT_INSTALMENT_min_min', 'client_cash_CNT_INSTALMENT_min_sum', 'client_cash_CNT_INSTALMENT_sum_mean', 'client_cash_CNT_INSTALMENT_sum_max', 'client_cash_CNT_INSTALMENT_sum_min', 'client_cash_CNT_INSTALMENT_sum_sum', 'client_cash_CNT_INSTALMENT_FUTURE_mean_mean', 'client_cash_CNT_INSTALMENT_FUTURE_mean_max', 'client_cash_CNT_INSTALMENT_FUTURE_mean_min', 'client_cash_CNT_INSTALMENT_FUTURE_mean_sum', 'client_cash_CNT_INSTALMENT_FUTURE_max_mean', 'client_cash_CNT_INSTALMENT_FUTURE_max_max', 'client_cash_CNT_INSTALMENT_FUTURE_max_min', 'client_cash_CNT_INSTALMENT_FUTURE_max_sum', 'client_cash_CNT_INSTALMENT_FUTURE_min_max', 'client_cash_CNT_INSTALMENT_FUTURE_min_sum', 'client_cash_CNT_INSTALMENT_FUTURE_sum_mean', 'client_cash_CNT_INSTALMENT_FUTURE_sum_max', 'client_cash_CNT_INSTALMENT_FUTURE_sum_min', 'client_cash_CNT_INSTALMENT_FUTURE_sum_sum', 'client_cash_SK_DPD_mean_mean', 'client_cash_SK_DPD_mean_max', 'client_cash_SK_DPD_mean_min', 'client_cash_SK_DPD_mean_sum', 'client_cash_SK_DPD_max_mean', 'client_cash_SK_DPD_max_max', 'client_cash_SK_DPD_max_min', 'client_cash_SK_DPD_max_sum', 'client_cash_SK_DPD_min_mean', 'client_cash_SK_DPD_min_max', 'client_cash_SK_DPD_min_sum', 'client_cash_SK_DPD_sum_mean', 'client_cash_SK_DPD_sum_max', 'client_cash_SK_DPD_sum_min', 'client_cash_SK_DPD_sum_sum', 'client_cash_SK_DPD_DEF_mean_mean', 'client_cash_SK_DPD_DEF_mean_max', 'client_cash_SK_DPD_DEF_mean_min', 'client_cash_SK_DPD_DEF_mean_sum', 'client_cash_SK_DPD_DEF_max_mean', 'client_cash_SK_DPD_DEF_max_max', 'client_cash_SK_DPD_DEF_max_min', 'client_cash_SK_DPD_DEF_max_sum', 'client_cash_SK_DPD_DEF_sum_mean', 'client_cash_SK_DPD_DEF_sum_max', 'client_cash_SK_DPD_DEF_sum_min', 'client_cash_SK_DPD_DEF_sum_sum', 'client_cash_counts_mean', 'client_cash_counts_min', 'client_cash_counts_sum', 'client_counts_x', 'client_credit_NAME_CONTRACT_STATUS_Active_count_mean', 'client_credit_NAME_CONTRACT_STATUS_Active_count_max', 'client_credit_NAME_CONTRACT_STATUS_Active_count_min', 'client_credit_NAME_CONTRACT_STATUS_Active_count_sum', 'client_credit_NAME_CONTRACT_STATUS_Active_count_norm_sum', 'client_credit_NAME_CONTRACT_STATUS_Completed_count_mean', 'client_credit_NAME_CONTRACT_STATUS_Completed_count_max', 'client_credit_NAME_CONTRACT_STATUS_Completed_count_min', 'client_credit_NAME_CONTRACT_STATUS_Completed_count_sum', 'client_credit_NAME_CONTRACT_STATUS_Completed_count_norm_sum', 'client_credit_NAME_CONTRACT_STATUS_Sent proposal_count_mean', 'client_credit_NAME_CONTRACT_STATUS_Sent proposal_count_max', 'client_credit_NAME_CONTRACT_STATUS_Sent proposal_count_min', 'client_credit_NAME_CONTRACT_STATUS_Sent proposal_count_sum', 'client_credit_NAME_CONTRACT_STATUS_Sent proposal_count_norm_sum', 'client_credit_NAME_CONTRACT_STATUS_Signed_count_mean', 'client_credit_NAME_CONTRACT_STATUS_Signed_count_max', 'client_credit_NAME_CONTRACT_STATUS_Signed_count_min', 'client_credit_NAME_CONTRACT_STATUS_Signed_count_sum', 'client_credit_NAME_CONTRACT_STATUS_Signed_count_norm_sum', 'client_credit_SK_ID_CURR_mean_mean', 'client_credit_SK_ID_CURR_mean_max', 'client_credit_SK_ID_CURR_mean_min', 'client_credit_SK_ID_CURR_mean_sum', 'client_credit_SK_ID_CURR_max_mean', 'client_credit_SK_ID_CURR_max_max', 'client_credit_SK_ID_CURR_max_min', 'client_credit_SK_ID_CURR_max_sum', 'client_credit_SK_ID_CURR_min_mean', 'client_credit_SK_ID_CURR_min_max', 'client_credit_SK_ID_CURR_min_min', 'client_credit_SK_ID_CURR_min_sum', 'client_credit_SK_ID_CURR_sum_mean', 'client_credit_SK_ID_CURR_sum_max', 'client_credit_SK_ID_CURR_sum_min', 'client_credit_SK_ID_CURR_sum_sum', 'client_credit_AMT_BALANCE_mean_mean', 'client_credit_AMT_BALANCE_mean_max', 'client_credit_AMT_BALANCE_mean_min', 'client_credit_AMT_BALANCE_mean_sum', 'client_credit_AMT_BALANCE_max_mean', 'client_credit_AMT_BALANCE_max_max', 'client_credit_AMT_BALANCE_max_min', 'client_credit_AMT_BALANCE_max_sum', 'client_credit_AMT_BALANCE_min_mean', 'client_credit_AMT_BALANCE_min_max', 'client_credit_AMT_BALANCE_min_min', 'client_credit_AMT_BALANCE_min_sum', 'client_credit_AMT_BALANCE_sum_mean', 'client_credit_AMT_BALANCE_sum_max', 'client_credit_AMT_BALANCE_sum_min', 'client_credit_AMT_BALANCE_sum_sum', 'client_credit_AMT_CREDIT_LIMIT_ACTUAL_mean_mean', 'client_credit_AMT_CREDIT_LIMIT_ACTUAL_mean_max', 'client_credit_AMT_CREDIT_LIMIT_ACTUAL_mean_min', 'client_credit_AMT_CREDIT_LIMIT_ACTUAL_mean_sum', 'client_credit_AMT_CREDIT_LIMIT_ACTUAL_max_mean', 'client_credit_AMT_CREDIT_LIMIT_ACTUAL_max_max', 'client_credit_AMT_CREDIT_LIMIT_ACTUAL_max_min', 'client_credit_AMT_CREDIT_LIMIT_ACTUAL_max_sum', 'client_credit_AMT_CREDIT_LIMIT_ACTUAL_min_mean', 'client_credit_AMT_CREDIT_LIMIT_ACTUAL_min_max', 'client_credit_AMT_CREDIT_LIMIT_ACTUAL_min_min', 'client_credit_AMT_CREDIT_LIMIT_ACTUAL_min_sum', 'client_credit_AMT_CREDIT_LIMIT_ACTUAL_sum_mean', 'client_credit_AMT_CREDIT_LIMIT_ACTUAL_sum_max', 'client_credit_AMT_CREDIT_LIMIT_ACTUAL_sum_min', 'client_credit_AMT_CREDIT_LIMIT_ACTUAL_sum_sum', 'client_credit_AMT_DRAWINGS_ATM_CURRENT_mean_mean', 'client_credit_AMT_DRAWINGS_ATM_CURRENT_mean_max', 'client_credit_AMT_DRAWINGS_ATM_CURRENT_mean_min', 'client_credit_AMT_DRAWINGS_ATM_CURRENT_mean_sum', 'client_credit_AMT_DRAWINGS_ATM_CURRENT_max_mean', 'client_credit_AMT_DRAWINGS_ATM_CURRENT_max_max', 'client_credit_AMT_DRAWINGS_ATM_CURRENT_max_min', 'client_credit_AMT_DRAWINGS_ATM_CURRENT_max_sum', 'client_credit_AMT_DRAWINGS_ATM_CURRENT_min_mean', 'client_credit_AMT_DRAWINGS_ATM_CURRENT_min_max', 'client_credit_AMT_DRAWINGS_ATM_CURRENT_min_min', 'client_credit_AMT_DRAWINGS_ATM_CURRENT_min_sum', 'client_credit_AMT_DRAWINGS_ATM_CURRENT_sum_mean', 'client_credit_AMT_DRAWINGS_ATM_CURRENT_sum_max', 'client_credit_AMT_DRAWINGS_ATM_CURRENT_sum_min', 'client_credit_AMT_DRAWINGS_ATM_CURRENT_sum_sum', 'client_credit_AMT_DRAWINGS_CURRENT_mean_mean', 'client_credit_AMT_DRAWINGS_CURRENT_mean_max', 'client_credit_AMT_DRAWINGS_CURRENT_mean_min', 'client_credit_AMT_DRAWINGS_CURRENT_mean_sum', 'client_credit_AMT_DRAWINGS_CURRENT_max_mean', 'client_credit_AMT_DRAWINGS_CURRENT_max_max', 'client_credit_AMT_DRAWINGS_CURRENT_max_min', 'client_credit_AMT_DRAWINGS_CURRENT_max_sum', 'client_credit_AMT_DRAWINGS_CURRENT_min_mean', 'client_credit_AMT_DRAWINGS_CURRENT_min_max', 'client_credit_AMT_DRAWINGS_CURRENT_min_min', 'client_credit_AMT_DRAWINGS_CURRENT_min_sum', 'client_credit_AMT_DRAWINGS_CURRENT_sum_mean', 'client_credit_AMT_DRAWINGS_CURRENT_sum_max', 'client_credit_AMT_DRAWINGS_CURRENT_sum_min', 'client_credit_AMT_DRAWINGS_CURRENT_sum_sum', 'client_credit_AMT_DRAWINGS_OTHER_CURRENT_mean_mean', 'client_credit_AMT_DRAWINGS_OTHER_CURRENT_mean_max', 'client_credit_AMT_DRAWINGS_OTHER_CURRENT_mean_min', 'client_credit_AMT_DRAWINGS_OTHER_CURRENT_mean_sum', 'client_credit_AMT_DRAWINGS_OTHER_CURRENT_max_mean', 'client_credit_AMT_DRAWINGS_OTHER_CURRENT_max_max', 'client_credit_AMT_DRAWINGS_OTHER_CURRENT_max_min', 'client_credit_AMT_DRAWINGS_OTHER_CURRENT_max_sum', 'client_credit_AMT_DRAWINGS_OTHER_CURRENT_sum_mean', 'client_credit_AMT_DRAWINGS_OTHER_CURRENT_sum_max', 'client_credit_AMT_DRAWINGS_OTHER_CURRENT_sum_min', 'client_credit_AMT_DRAWINGS_OTHER_CURRENT_sum_sum', 'client_credit_AMT_DRAWINGS_POS_CURRENT_mean_mean', 'client_credit_AMT_DRAWINGS_POS_CURRENT_mean_max', 'client_credit_AMT_DRAWINGS_POS_CURRENT_mean_min', 'client_credit_AMT_DRAWINGS_POS_CURRENT_mean_sum', 'client_credit_AMT_DRAWINGS_POS_CURRENT_max_mean', 'client_credit_AMT_DRAWINGS_POS_CURRENT_max_max', 'client_credit_AMT_DRAWINGS_POS_CURRENT_max_min', 'client_credit_AMT_DRAWINGS_POS_CURRENT_max_sum', 'client_credit_AMT_DRAWINGS_POS_CURRENT_min_mean', 'client_credit_AMT_DRAWINGS_POS_CURRENT_min_max', 'client_credit_AMT_DRAWINGS_POS_CURRENT_min_min', 'client_credit_AMT_DRAWINGS_POS_CURRENT_min_sum', 'client_credit_AMT_DRAWINGS_POS_CURRENT_sum_mean', 'client_credit_AMT_DRAWINGS_POS_CURRENT_sum_max', 'client_credit_AMT_DRAWINGS_POS_CURRENT_sum_min', 'client_credit_AMT_DRAWINGS_POS_CURRENT_sum_sum', 'client_credit_AMT_INST_MIN_REGULARITY_mean_mean', 'client_credit_AMT_INST_MIN_REGULARITY_mean_max', 'client_credit_AMT_INST_MIN_REGULARITY_mean_min', 'client_credit_AMT_INST_MIN_REGULARITY_mean_sum', 'client_credit_AMT_INST_MIN_REGULARITY_max_mean', 'client_credit_AMT_INST_MIN_REGULARITY_max_max', 'client_credit_AMT_INST_MIN_REGULARITY_max_min', 'client_credit_AMT_INST_MIN_REGULARITY_max_sum', 'client_credit_AMT_INST_MIN_REGULARITY_min_mean', 'client_credit_AMT_INST_MIN_REGULARITY_min_max', 'client_credit_AMT_INST_MIN_REGULARITY_min_min', 'client_credit_AMT_INST_MIN_REGULARITY_min_sum', 'client_credit_AMT_INST_MIN_REGULARITY_sum_mean', 'client_credit_AMT_INST_MIN_REGULARITY_sum_max', 'client_credit_AMT_INST_MIN_REGULARITY_sum_min', 'client_credit_AMT_INST_MIN_REGULARITY_sum_sum', 'client_credit_AMT_PAYMENT_CURRENT_mean_mean', 'client_credit_AMT_PAYMENT_CURRENT_mean_max', 'client_credit_AMT_PAYMENT_CURRENT_mean_min', 'client_credit_AMT_PAYMENT_CURRENT_mean_sum', 'client_credit_AMT_PAYMENT_CURRENT_max_mean', 'client_credit_AMT_PAYMENT_CURRENT_max_max', 'client_credit_AMT_PAYMENT_CURRENT_max_min', 'client_credit_AMT_PAYMENT_CURRENT_max_sum', 'client_credit_AMT_PAYMENT_CURRENT_min_mean', 'client_credit_AMT_PAYMENT_CURRENT_min_max', 'client_credit_AMT_PAYMENT_CURRENT_min_min', 'client_credit_AMT_PAYMENT_CURRENT_min_sum', 'client_credit_AMT_PAYMENT_CURRENT_sum_mean', 'client_credit_AMT_PAYMENT_CURRENT_sum_max', 'client_credit_AMT_PAYMENT_CURRENT_sum_min', 'client_credit_AMT_PAYMENT_CURRENT_sum_sum', 'client_credit_AMT_PAYMENT_TOTAL_CURRENT_mean_mean', 'client_credit_AMT_PAYMENT_TOTAL_CURRENT_mean_max', 'client_credit_AMT_PAYMENT_TOTAL_CURRENT_mean_min', 'client_credit_AMT_PAYMENT_TOTAL_CURRENT_mean_sum', 'client_credit_AMT_PAYMENT_TOTAL_CURRENT_max_mean', 'client_credit_AMT_PAYMENT_TOTAL_CURRENT_max_max', 'client_credit_AMT_PAYMENT_TOTAL_CURRENT_max_min', 'client_credit_AMT_PAYMENT_TOTAL_CURRENT_max_sum', 'client_credit_AMT_PAYMENT_TOTAL_CURRENT_min_mean', 'client_credit_AMT_PAYMENT_TOTAL_CURRENT_min_max', 'client_credit_AMT_PAYMENT_TOTAL_CURRENT_min_min', 'client_credit_AMT_PAYMENT_TOTAL_CURRENT_min_sum', 'client_credit_AMT_PAYMENT_TOTAL_CURRENT_sum_mean', 'client_credit_AMT_PAYMENT_TOTAL_CURRENT_sum_max', 'client_credit_AMT_PAYMENT_TOTAL_CURRENT_sum_min', 'client_credit_AMT_PAYMENT_TOTAL_CURRENT_sum_sum', 'client_credit_AMT_RECEIVABLE_PRINCIPAL_mean_mean', 'client_credit_AMT_RECEIVABLE_PRINCIPAL_mean_max', 'client_credit_AMT_RECEIVABLE_PRINCIPAL_mean_min', 'client_credit_AMT_RECEIVABLE_PRINCIPAL_mean_sum', 'client_credit_AMT_RECEIVABLE_PRINCIPAL_max_mean', 'client_credit_AMT_RECEIVABLE_PRINCIPAL_max_max', 'client_credit_AMT_RECEIVABLE_PRINCIPAL_max_min', 'client_credit_AMT_RECEIVABLE_PRINCIPAL_max_sum', 'client_credit_AMT_RECEIVABLE_PRINCIPAL_min_mean', 'client_credit_AMT_RECEIVABLE_PRINCIPAL_min_max', 'client_credit_AMT_RECEIVABLE_PRINCIPAL_min_min', 'client_credit_AMT_RECEIVABLE_PRINCIPAL_min_sum', 'client_credit_AMT_RECEIVABLE_PRINCIPAL_sum_mean', 'client_credit_AMT_RECEIVABLE_PRINCIPAL_sum_max', 'client_credit_AMT_RECEIVABLE_PRINCIPAL_sum_min', 'client_credit_AMT_RECEIVABLE_PRINCIPAL_sum_sum', 'client_credit_AMT_RECIVABLE_mean_mean', 'client_credit_AMT_RECIVABLE_mean_max', 'client_credit_AMT_RECIVABLE_mean_min', 'client_credit_AMT_RECIVABLE_mean_sum', 'client_credit_AMT_RECIVABLE_max_mean', 'client_credit_AMT_RECIVABLE_max_max', 'client_credit_AMT_RECIVABLE_max_min', 'client_credit_AMT_RECIVABLE_max_sum', 'client_credit_AMT_RECIVABLE_min_mean', 'client_credit_AMT_RECIVABLE_min_max', 'client_credit_AMT_RECIVABLE_min_min', 'client_credit_AMT_RECIVABLE_min_sum', 'client_credit_AMT_RECIVABLE_sum_mean', 'client_credit_AMT_RECIVABLE_sum_max', 'client_credit_AMT_RECIVABLE_sum_min', 'client_credit_AMT_RECIVABLE_sum_sum', 'client_credit_AMT_TOTAL_RECEIVABLE_mean_mean', 'client_credit_AMT_TOTAL_RECEIVABLE_mean_max', 'client_credit_AMT_TOTAL_RECEIVABLE_mean_min', 'client_credit_AMT_TOTAL_RECEIVABLE_mean_sum', 'client_credit_AMT_TOTAL_RECEIVABLE_max_mean', 'client_credit_AMT_TOTAL_RECEIVABLE_max_max', 'client_credit_AMT_TOTAL_RECEIVABLE_max_min', 'client_credit_AMT_TOTAL_RECEIVABLE_max_sum', 'client_credit_AMT_TOTAL_RECEIVABLE_min_mean', 'client_credit_AMT_TOTAL_RECEIVABLE_min_max', 'client_credit_AMT_TOTAL_RECEIVABLE_min_min', 'client_credit_AMT_TOTAL_RECEIVABLE_min_sum', 'client_credit_AMT_TOTAL_RECEIVABLE_sum_mean', 'client_credit_AMT_TOTAL_RECEIVABLE_sum_max', 'client_credit_AMT_TOTAL_RECEIVABLE_sum_min', 'client_credit_AMT_TOTAL_RECEIVABLE_sum_sum', 'client_credit_CNT_DRAWINGS_ATM_CURRENT_mean_mean', 'client_credit_CNT_DRAWINGS_ATM_CURRENT_mean_max', 'client_credit_CNT_DRAWINGS_ATM_CURRENT_mean_min', 'client_credit_CNT_DRAWINGS_ATM_CURRENT_mean_sum', 'client_credit_CNT_DRAWINGS_ATM_CURRENT_max_mean', 'client_credit_CNT_DRAWINGS_ATM_CURRENT_max_max', 'client_credit_CNT_DRAWINGS_ATM_CURRENT_max_min', 'client_credit_CNT_DRAWINGS_ATM_CURRENT_max_sum', 'client_credit_CNT_DRAWINGS_ATM_CURRENT_min_mean', 'client_credit_CNT_DRAWINGS_ATM_CURRENT_min_max', 'client_credit_CNT_DRAWINGS_ATM_CURRENT_min_min', 'client_credit_CNT_DRAWINGS_ATM_CURRENT_min_sum', 'client_credit_CNT_DRAWINGS_ATM_CURRENT_sum_mean', 'client_credit_CNT_DRAWINGS_ATM_CURRENT_sum_max', 'client_credit_CNT_DRAWINGS_ATM_CURRENT_sum_min', 'client_credit_CNT_DRAWINGS_ATM_CURRENT_sum_sum', 'client_credit_CNT_DRAWINGS_CURRENT_mean_mean', 'client_credit_CNT_DRAWINGS_CURRENT_mean_max', 'client_credit_CNT_DRAWINGS_CURRENT_mean_min', 'client_credit_CNT_DRAWINGS_CURRENT_mean_sum', 'client_credit_CNT_DRAWINGS_CURRENT_max_mean', 'client_credit_CNT_DRAWINGS_CURRENT_max_max', 'client_credit_CNT_DRAWINGS_CURRENT_max_min', 'client_credit_CNT_DRAWINGS_CURRENT_max_sum', 'client_credit_CNT_DRAWINGS_CURRENT_min_mean', 'client_credit_CNT_DRAWINGS_CURRENT_min_max', 'client_credit_CNT_DRAWINGS_CURRENT_min_min', 'client_credit_CNT_DRAWINGS_CURRENT_min_sum', 'client_credit_CNT_DRAWINGS_CURRENT_sum_mean', 'client_credit_CNT_DRAWINGS_CURRENT_sum_max', 'client_credit_CNT_DRAWINGS_CURRENT_sum_min', 'client_credit_CNT_DRAWINGS_CURRENT_sum_sum', 'client_credit_CNT_DRAWINGS_OTHER_CURRENT_mean_sum', 'client_credit_CNT_DRAWINGS_OTHER_CURRENT_max_sum', 'client_credit_CNT_DRAWINGS_OTHER_CURRENT_sum_mean', 'client_credit_CNT_DRAWINGS_OTHER_CURRENT_sum_max', 'client_credit_CNT_DRAWINGS_OTHER_CURRENT_sum_min', 'client_credit_CNT_DRAWINGS_OTHER_CURRENT_sum_sum', 'client_credit_CNT_DRAWINGS_POS_CURRENT_mean_mean', 'client_credit_CNT_DRAWINGS_POS_CURRENT_mean_max', 'client_credit_CNT_DRAWINGS_POS_CURRENT_mean_min', 'client_credit_CNT_DRAWINGS_POS_CURRENT_mean_sum', 'client_credit_CNT_DRAWINGS_POS_CURRENT_max_mean', 'client_credit_CNT_DRAWINGS_POS_CURRENT_max_max', 'client_credit_CNT_DRAWINGS_POS_CURRENT_max_min', 'client_credit_CNT_DRAWINGS_POS_CURRENT_max_sum', 'client_credit_CNT_DRAWINGS_POS_CURRENT_min_mean', 'client_credit_CNT_DRAWINGS_POS_CURRENT_min_max', 'client_credit_CNT_DRAWINGS_POS_CURRENT_min_min', 'client_credit_CNT_DRAWINGS_POS_CURRENT_min_sum', 'client_credit_CNT_DRAWINGS_POS_CURRENT_sum_mean', 'client_credit_CNT_DRAWINGS_POS_CURRENT_sum_max', 'client_credit_CNT_DRAWINGS_POS_CURRENT_sum_min', 'client_credit_CNT_DRAWINGS_POS_CURRENT_sum_sum', 'client_credit_CNT_INSTALMENT_MATURE_CUM_mean_mean', 'client_credit_CNT_INSTALMENT_MATURE_CUM_mean_max', 'client_credit_CNT_INSTALMENT_MATURE_CUM_mean_min', 'client_credit_CNT_INSTALMENT_MATURE_CUM_mean_sum', 'client_credit_CNT_INSTALMENT_MATURE_CUM_max_mean', 'client_credit_CNT_INSTALMENT_MATURE_CUM_max_max', 'client_credit_CNT_INSTALMENT_MATURE_CUM_max_min', 'client_credit_CNT_INSTALMENT_MATURE_CUM_max_sum', 'client_credit_CNT_INSTALMENT_MATURE_CUM_min_mean', 'client_credit_CNT_INSTALMENT_MATURE_CUM_min_max', 'client_credit_CNT_INSTALMENT_MATURE_CUM_min_min', 'client_credit_CNT_INSTALMENT_MATURE_CUM_min_sum', 'client_credit_CNT_INSTALMENT_MATURE_CUM_sum_mean', 'client_credit_CNT_INSTALMENT_MATURE_CUM_sum_max', 'client_credit_CNT_INSTALMENT_MATURE_CUM_sum_min', 'client_credit_CNT_INSTALMENT_MATURE_CUM_sum_sum', 'client_credit_SK_DPD_mean_mean', 'client_credit_SK_DPD_mean_max', 'client_credit_SK_DPD_mean_min', 'client_credit_SK_DPD_mean_sum', 'client_credit_SK_DPD_max_mean', 'client_credit_SK_DPD_max_max', 'client_credit_SK_DPD_max_min', 'client_credit_SK_DPD_max_sum', 'client_credit_SK_DPD_sum_mean', 'client_credit_SK_DPD_sum_max', 'client_credit_SK_DPD_sum_min', 'client_credit_SK_DPD_sum_sum', 'client_credit_SK_DPD_DEF_mean_mean', 'client_credit_SK_DPD_DEF_mean_max', 'client_credit_SK_DPD_DEF_mean_min', 'client_credit_SK_DPD_DEF_mean_sum', 'client_credit_SK_DPD_DEF_max_mean', 'client_credit_SK_DPD_DEF_max_max', 'client_credit_SK_DPD_DEF_max_min', 'client_credit_SK_DPD_DEF_max_sum', 'client_credit_SK_DPD_DEF_sum_mean', 'client_credit_SK_DPD_DEF_sum_max', 'client_credit_SK_DPD_DEF_sum_min', 'client_credit_SK_DPD_DEF_sum_sum', 'client_credit_counts_mean', 'client_credit_counts_max', 'client_credit_counts_min', 'client_credit_counts_sum', 'client_counts_y', 'client_installments_SK_ID_CURR_mean_mean', 'client_installments_SK_ID_CURR_mean_max', 'client_installments_SK_ID_CURR_mean_min', 'client_installments_SK_ID_CURR_mean_sum', 'client_installments_SK_ID_CURR_max_mean', 'client_installments_SK_ID_CURR_max_max', 'client_installments_SK_ID_CURR_max_min', 'client_installments_SK_ID_CURR_max_sum', 'client_installments_SK_ID_CURR_min_mean', 'client_installments_SK_ID_CURR_min_max', 'client_installments_SK_ID_CURR_min_min', 'client_installments_SK_ID_CURR_min_sum', 'client_installments_SK_ID_CURR_sum_mean', 'client_installments_SK_ID_CURR_sum_max', 'client_installments_SK_ID_CURR_sum_min', 'client_installments_SK_ID_CURR_sum_sum', 'client_installments_NUM_INSTALMENT_VERSION_mean_max', 'client_installments_NUM_INSTALMENT_VERSION_mean_min', 'client_installments_NUM_INSTALMENT_VERSION_mean_sum', 'client_installments_NUM_INSTALMENT_VERSION_max_max', 'client_installments_NUM_INSTALMENT_VERSION_max_min', 'client_installments_NUM_INSTALMENT_VERSION_max_sum', 'client_installments_NUM_INSTALMENT_VERSION_min_mean', 'client_installments_NUM_INSTALMENT_VERSION_min_max', 'client_installments_NUM_INSTALMENT_VERSION_min_min', 'client_installments_NUM_INSTALMENT_VERSION_min_sum', 'client_installments_NUM_INSTALMENT_VERSION_sum_mean', 'client_installments_NUM_INSTALMENT_VERSION_sum_max', 'client_installments_NUM_INSTALMENT_VERSION_sum_min', 'client_installments_NUM_INSTALMENT_VERSION_sum_sum', 'client_installments_NUM_INSTALMENT_NUMBER_mean_mean', 'client_installments_NUM_INSTALMENT_NUMBER_mean_max', 'client_installments_NUM_INSTALMENT_NUMBER_mean_min', 'client_installments_NUM_INSTALMENT_NUMBER_mean_sum', 'client_installments_NUM_INSTALMENT_NUMBER_max_mean', 'client_installments_NUM_INSTALMENT_NUMBER_max_max', 'client_installments_NUM_INSTALMENT_NUMBER_max_min', 'client_installments_NUM_INSTALMENT_NUMBER_max_sum', 'client_installments_NUM_INSTALMENT_NUMBER_min_mean', 'client_installments_NUM_INSTALMENT_NUMBER_min_max', 'client_installments_NUM_INSTALMENT_NUMBER_min_sum', 'client_installments_NUM_INSTALMENT_NUMBER_sum_mean', 'client_installments_NUM_INSTALMENT_NUMBER_sum_max', 'client_installments_NUM_INSTALMENT_NUMBER_sum_min', 'client_installments_NUM_INSTALMENT_NUMBER_sum_sum', 'client_installments_AMT_INSTALMENT_mean_mean', 'client_installments_AMT_INSTALMENT_mean_max', 'client_installments_AMT_INSTALMENT_mean_min', 'client_installments_AMT_INSTALMENT_mean_sum', 'client_installments_AMT_INSTALMENT_max_mean', 'client_installments_AMT_INSTALMENT_max_max', 'client_installments_AMT_INSTALMENT_max_min', 'client_installments_AMT_INSTALMENT_max_sum', 'client_installments_AMT_INSTALMENT_min_mean', 'client_installments_AMT_INSTALMENT_min_max', 'client_installments_AMT_INSTALMENT_min_min', 'client_installments_AMT_INSTALMENT_min_sum', 'client_installments_AMT_INSTALMENT_sum_mean', 'client_installments_AMT_INSTALMENT_sum_max', 'client_installments_AMT_INSTALMENT_sum_min', 'client_installments_AMT_INSTALMENT_sum_sum', 'client_installments_AMT_PAYMENT_mean_mean', 'client_installments_AMT_PAYMENT_mean_max', 'client_installments_AMT_PAYMENT_mean_min', 'client_installments_AMT_PAYMENT_mean_sum', 'client_installments_AMT_PAYMENT_max_mean', 'client_installments_AMT_PAYMENT_max_max', 'client_installments_AMT_PAYMENT_max_min', 'client_installments_AMT_PAYMENT_max_sum', 'client_installments_AMT_PAYMENT_min_mean', 'client_installments_AMT_PAYMENT_min_max', 'client_installments_AMT_PAYMENT_min_min', 'client_installments_AMT_PAYMENT_min_sum', 'client_installments_AMT_PAYMENT_sum_mean', 'client_installments_AMT_PAYMENT_sum_max', 'client_installments_AMT_PAYMENT_sum_min', 'client_installments_AMT_PAYMENT_sum_sum', 'client_installments_counts_mean', 'client_installments_counts_max', 'client_installments_counts_min', 'client_installments_counts_sum', 'client_counts']
chi2_selector = SelectKBest(chi2, k=10) # Select top 5 features
X_train_kbest = chi2_selector.fit_transform(X_train, y_train)
# To get the selected feature names
selected_features = [feature for feature, mask in zip(X_train.columns, chi2_selector.get_support()) if mask]
print(selected_features)
['client_credit_SK_ID_CURR_sum_sum', 'client_credit_AMT_BALANCE_sum_sum', 'client_credit_AMT_CREDIT_LIMIT_ACTUAL_sum_sum', 'client_credit_AMT_PAYMENT_CURRENT_sum_sum', 'client_credit_AMT_PAYMENT_TOTAL_CURRENT_sum_sum', 'client_credit_AMT_RECEIVABLE_PRINCIPAL_sum_sum', 'client_credit_AMT_RECIVABLE_sum_sum', 'client_credit_AMT_TOTAL_RECEIVABLE_sum_sum', 'client_installments_SK_ID_CURR_sum_sum', 'client_installments_AMT_PAYMENT_sum_sum']
We can see that the top categorical variables are ‘client_credit_SK_ID_CURR_sum_sum’, ‘client_credit_AMT_CREDIT_LIMIT_ACTUAL_sum_sum’, ‘client_credit_AMT_TOTAL_RECEIVABLE_sum_sum’. Some of the top 10 of numerical variables are the balance of the client, the credit limit, the principal receivable.
Information gain (mutual information)
We can use the method SelectKBest in sklearn with several different algorithm such as mutual information, ANNOVA. These algorithms can process negative values. Mutual information is a non negative value that measures the dependency between the features and the target. It comes from information theory. It is equal to zero iff the two random variables are independent. Higher value would mean higher dependency which means that one variable becomes less uncertain when we know the value of the other one. Note that mutual information method doesn’t make assumption about the nature of the relationship, so it can capture non linear and non monotonic relation as well. Some other indicator such as correlation efficient can only capture linear relationship. Here is how to calculate the mutual information \(I(X,Y) = H(X) - H(X\mid Y)\). We can see that it is the difference betweeen the entropy for X and the conditional entropy for X given Y. The result is in bits. We only need to choose the corresponding algorithm for the SelectKBest method in sklearn. Since we have a thousand features, the dependency measurement for each variable is low, with the maximum being 0.03. Some of the top variables are about previous loan status, installment payment, actual credit limit, and cash loan purpose. It makes sense to use these features to predict the default rate of the client.
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
categoricals = ['object']
X_train = train.select_dtypes(include=numerics)
columns = X_train.columns
from sklearn.impute import SimpleImputer
import numpy as np
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
imputer = imputer.fit(X_train)
X_train = imputer.transform(X_train)
X_train = pd.DataFrame(data=X_train, columns=columns)
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import mutual_info_classif
# apply SelectKBest class to extract top 10 best features
bestfeatures = SelectKBest(score_func=mutual_info_classif, k=10)
fit = bestfeatures.fit(X_train, y_train) # X, y defined as before
dfscores = pd.DataFrame(fit.scores_)
dfcolumns = pd.DataFrame(X_train.columns)
# concatenate two dataframes for better visualization
featureScores = pd.concat([dfcolumns,dfscores],axis=1)
# name the dataframe columns
featureScores.columns = ['Specs','Score']
# print 10 best features
print(featureScores.nlargest(10,'Score'))
/Users/nguyenlinhchi/.local/lib/python3.9/site-packages/sklearn/utils/validation.py:1143: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
Specs Score
299 previous_loans_NAME_PORTFOLIO_POS_count 0.030435
1130 client_installments_AMT_PAYMENT_mean_min 0.024786
913 client_credit_AMT_TOTAL_RECEIVABLE_sum_min 0.024512
574 client_cash_CNT_INSTALMENT_min_mean 0.023053
741 client_credit_AMT_CREDIT_LIMIT_ACTUAL_mean_min 0.022686
768 client_credit_AMT_DRAWINGS_ATM_CURRENT_sum_max 0.022160
352 previous_loans_NAME_YIELD_GROUP_low_action_cou... 0.021542
157 previous_loans_NAME_CASH_LOAN_PURPOSE_Journey_... 0.021407
30 EXT_SOURCE_3 0.021029
965 client_credit_CNT_DRAWINGS_POS_CURRENT_mean_min 0.020707
ANNOVA F-test
ANNOVA, short for analysis of variance, is a statistical test that can decode the correlation among the features. It can test the equality of the means among populations too. This method can see the difference between systematic component and random factors affecting the observed variability of a dataset. This information can be used to evaluate the impact of features on the target. The equation for ANNOVA for one feature is \(\frac{distance between classes}{compactness of classes}\). This ratio shows how good the feature is in predicting the classes of a variable (how good it contributes to separate them).
For example, we have two classes for feature X separating: Class 1: [800, 300, 1300] and Class 2: [1000, 2000]. First we take the average of all points: (800 + 300 + 1300 + 1000 + 2000) / 5 = 1080. Then the mean of class 1: 800, mean of class 2: 1500. The distance between classes would be calculated as follows: number of observations in class 1 * (mean 1 - mean)^2 + number of observations in class 2 * (mean 2 - mean)^2 = 3 * (800 - 1080)^2 + 2 * (1500 - 1080)^2 = 588000. The compactness of the classes is calculated as: \(\frac{sample variance 1 + sample variance 2}{number of observations 1 - 1 + number of observations 2 - 1}\), with sample variance for each class being \(\frac{\sum_i (x_i - \bar{x})^2}{n-1}\). \(Sample variance 1 = \frac{(800-800)^2+(300-800)^2+(1300-800)^2}{3-1} = 250000\). \(sample variance 2 = 500000\). So the compactness is \(250000\). The F-score = 2.352. The degrees of freedom for the numerator is the number of groups minus one which is 1 and the second degrees of freedom is the total number of observations minus the number of groups, which is 5 - 2 = 3. Looking up the critical value for our configuration in the table of F test, the critical value is 5.53 which is larger than the calculated value. We cannot reject the null hypothesis that the feature X doesn’t have significant impact on the target variable. Since the mean of the two classes divided by the feature is equal.
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
categoricals = ['object']
X_train = train.select_dtypes(include=numerics)
columns = X_train.columns
from sklearn.impute import SimpleImputer
import numpy as np
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
imputer = imputer.fit(X_train)
X_train = imputer.transform(X_train)
X_train = pd.DataFrame(data=X_train, columns=columns)
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_classif
# apply SelectKBest class to extract top 10 best features
bestfeatures = SelectKBest(score_func=f_classif, k=10)
fit = bestfeatures.fit(X_train, y_train) # X, y defined as before
dfscores = pd.DataFrame(fit.scores_)
dfcolumns = pd.DataFrame(X_train.columns)
# concatenate two dataframes for better visualization
featureScores = pd.concat([dfcolumns,dfscores],axis=1)
# name the dataframe columns
featureScores.columns = ['Specs','Score']
# print 10 best features
print(featureScores.nlargest(10,'Score'))
Specs Score
30 EXT_SOURCE_3 44.139397
29 EXT_SOURCE_2 39.448303
167 previous_loans_NAME_CASH_LOAN_PURPOSE_Purchase... 13.564337
168 previous_loans_NAME_CASH_LOAN_PURPOSE_Purchase... 13.564337
146 previous_loans_NAME_CASH_LOAN_PURPOSE_Car repa... 12.410798
200 previous_loans_CODE_REJECT_REASON_HC_count_norm 11.547177
212 previous_loans_CODE_REJECT_REASON_XAP_count_norm 11.498345
288 previous_loans_NAME_GOODS_CATEGORY_Vehicles_co... 11.284404
186 previous_loans_NAME_CONTRACT_STATUS_Refused_co... 11.032108
350 previous_loans_NAME_YIELD_GROUP_high_count_norm 10.263603
/Users/nguyenlinhchi/.local/lib/python3.9/site-packages/sklearn/utils/validation.py:1143: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/Users/nguyenlinhchi/.local/lib/python3.9/site-packages/sklearn/feature_selection/_univariate_selection.py:112: UserWarning: Features [ 12 79 81 84 87 89 94 96 97 98 133 134 135 136
139 140 153 154 155 156 161 162 169 170 237 238 239 240
255 256 257 258 265 266 267 268 341 342 416 470 471 472
473 474 475 476 477 486 487 488 489 490 491 492 493 502
503 504 505 506 507 508 509 526 527 528 529 530 531 532
533 608 622 623 624 625 643 644 645 646 647 648 649 650
659 660 661 662 663 664 665 666 667 668 669 670 671 672
673 674 795 796 797 798 955 956 957 958 1003 1004 1005 1006
1019 1020 1021 1022] are constant.
warnings.warn("Features %s are constant." % constant_features_idx, UserWarning)
/Users/nguyenlinhchi/.local/lib/python3.9/site-packages/sklearn/feature_selection/_univariate_selection.py:113: RuntimeWarning: invalid value encountered in divide
f = msb / msw
Correlation coefficient
This is the indicator of correlation between target variable and the input variables, it selects the highly correlated features with the target. It is a simple technique.
import seaborn as sns
#Using Pearson Correlation
plt.figure(figsize=(12,10))
cor = X_train.corr()
sns.heatmap(cor, annot=True, cmap=plt.cm.Reds)
plt.show()
Wrapper method
Forward selection
This starts with an empty model. In each step, it considers all the available model and chooses the one that add the most to the performance of the model. The process is repeated until adding more variables to the model doesn’t improve it anymore. This is a greedy algorithm, meaning that it chooses the immediate best at the current step without thinking about the consequences.
So basically we start with a null main model, this assumes that none of the features can explain the variance in the target. Then we fit a simple sub-model for each feature. We choose the feature that is with the sub-model producing the lowest p-value (highest statistical significance) to add to our main model. Then we fit sub-models with two predictors, one of which is the one already selected, the other is each of the rest. Then we choose the second predictor for our main model by choosing the one associated with the sub-model having the lowest p-value. Repeat the process until a stopping criterion.
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
categoricals = ['object']
X_train = train.select_dtypes(include=categoricals)
columns = X_train.columns
from sklearn.impute import SimpleImputer
import numpy as np
imputer = SimpleImputer(missing_values=np.nan, strategy='most_frequent')
imputer = imputer.fit(X_train)
X_train = imputer.transform(X_train)
X_train = pd.DataFrame(data=X_train, columns=columns)
X_train = X_train.apply(LabelEncoder().fit_transform)
import statsmodels.api as sm
# List of all potential features
features = list(X_train.columns)
# The maximum p-value for features we'll accept as significant
p_max = 0.05
while len(features) > 0:
features_with_constant = sm.add_constant(X_train[features])
p_values = sm.OLS(y_train, features_with_constant).fit().pvalues[1:]
max_p_value = p_values.max()
if max_p_value >= p_max:
excluded_feature = p_values.idxmax()
features.remove(excluded_feature)
else:
break
print(f'Selected features: {features}')
Selected features: ['CODE_GENDER', 'NAME_EDUCATION_TYPE']
sm.OLS(y_train, features_with_constant).fit().summary()
| Dep. Variable: | TARGET | R-squared: | 0.012 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.010 |
| Method: | Least Squares | F-statistic: | 6.041 |
| Date: | Thu, 01 Jun 2023 | Prob (F-statistic): | 0.00247 |
| Time: | 20:05:18 | Log-Likelihood: | -47.001 |
| No. Observations: | 1000 | AIC: | 100.0 |
| Df Residuals: | 997 | BIC: | 114.7 |
| Df Model: | 2 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 0.0231 | 0.016 | 1.414 | 0.158 | -0.009 | 0.055 |
| CODE_GENDER | 0.0378 | 0.017 | 2.252 | 0.025 | 0.005 | 0.071 |
| NAME_EDUCATION_TYPE | 0.0155 | 0.006 | 2.551 | 0.011 | 0.004 | 0.027 |
| Omnibus: | 683.755 | Durbin-Watson: | 1.987 |
|---|---|---|---|
| Prob(Omnibus): | 0.000 | Jarque-Bera (JB): | 5303.637 |
| Skew: | 3.310 | Prob(JB): | 0.00 |
| Kurtosis: | 12.136 | Cond. No. | 6.48 |
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
For the categorical variables, this method chooses only gender and education type.
Backward elimination
Backward elimination method is similar to the forward elimination but in reverse. It starts with a model full of features. It removes the least significant feature one at a time (having p-value smaller than the significance level of 0.05 for example), until no further improvement is observed. Basically, it fits the full model, then it plans to remove the feature with the highest p-value exceeding the chosen significance level. If there is no such feature, the process stops. Otherwise the feature is removed and the model would be fitted again without the eliminated.
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
categoricals = ['object']
X_train = train.select_dtypes(include=categoricals)
columns = X_train.columns
from sklearn.impute import SimpleImputer
import numpy as np
imputer = SimpleImputer(missing_values=np.nan, strategy='most_frequent')
imputer = imputer.fit(X_train)
X_train = imputer.transform(X_train)
X_train = pd.DataFrame(data=X_train, columns=columns)
X_train = X_train.apply(LabelEncoder().fit_transform)
import pandas as pd
import statsmodels.api as sm
# Add a column of ones as integer data type
X_train.insert(0, 'Intercept', 1)
# Set a significance level
SL = 0.05
# Convert the DataFrame into a list so that we can manipulate the features
features = list(X_train.columns)
while (len(features) > 0):
features_with_pvalues = []
excluded_feature = ''
# Fit the model with the current features
model = sm.OLS(y_train, X_train[features]).fit()
# Get the p-values for the features
pvalues = model.pvalues
max_pvalue = pvalues.max() # Get the feature with the highest p-value
if max_pvalue > SL:
excluded_feature = pvalues.idxmax() # Get the feature with the highest p-value
features.remove(excluded_feature)
else:
break
final_model = sm.OLS(y_train, X_train[features]).fit()
print(final_model.summary())
print(f"The final features are: {features}")
OLS Regression Results
=======================================================================================
Dep. Variable: TARGET R-squared (uncentered): 0.083
Model: OLS Adj. R-squared (uncentered): 0.081
Method: Least Squares F-statistic: 30.24
Date: Thu, 01 Jun 2023 Prob (F-statistic): 1.03e-18
Time: 20:06:00 Log-Likelihood: -45.766
No. Observations: 1000 AIC: 97.53
Df Residuals: 997 BIC: 112.3
Df Model: 3
Covariance Type: nonrobust
==============================================================================================
coef std err t P>|t| [0.025 0.975]
----------------------------------------------------------------------------------------------
CODE_GENDER 0.0393 0.016 2.438 0.015 0.008 0.071
NAME_EDUCATION_TYPE 0.0162 0.005 3.438 0.001 0.007 0.025
WEEKDAY_APPR_PROCESS_START 0.0065 0.003 2.114 0.035 0.000 0.013
==============================================================================
Omnibus: 679.118 Durbin-Watson: 1.983
Prob(Omnibus): 0.000 Jarque-Bera (JB): 5201.242
Skew: 3.285 Prob(JB): 0.00
Kurtosis: 12.036 Cond. No. 8.60
==============================================================================
Notes:
[1] R² is computed without centering (uncentered) since the model does not contain a constant.
[2] Standard Errors assume that the covariance matrix of the errors is correctly specified.
The final features are: ['CODE_GENDER', 'NAME_EDUCATION_TYPE', 'WEEKDAY_APPR_PROCESS_START']
Interestingly, this process chooses the same two variables above: the gender and the education type, it chooses another one named the day of the week when the client starts the process.
Recursive feature elimination (RFE)
This algorithm performs a greedy search to find the best performing feature subset. In each iteration, it creates model and determine the best and worst features. Then it builds the next model with the best ones until the number of features we need is reached. The features are then ranked based on the order of their elimination. The top three categorical variables that are chosen are the gender, contract type and whether the client owns a car. The difference with backward elimination is that this method uses a metric of model performance to decide the weakest feature. For example it can use accuracy instead of p-value.
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
categoricals = ['object']
X_train = train.select_dtypes(include=categoricals)
columns = X_train.columns
from sklearn.impute import SimpleImputer
import numpy as np
imputer = SimpleImputer(missing_values=np.nan, strategy='most_frequent')
imputer = imputer.fit(X_train)
X_train = imputer.transform(X_train)
X_train = pd.DataFrame(data=X_train, columns=columns)
X_train = X_train.apply(LabelEncoder().fit_transform)
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
# feature extraction
model = LogisticRegression()
rfe = RFE(estimator=model, n_features_to_select=3)
fit = rfe.fit(X_train, y_train)
# get column names
col_names = X_train.columns
# get selected features
selected_features = col_names[fit.support_]
print("Selected Features: ")
for feature in selected_features:
print(feature)
Selected Features:
NAME_CONTRACT_TYPE
CODE_GENDER
FLAG_OWN_CAR
Embedded method
This method chooses the features as a part of the creation of the model.
LASSO
LASSO has been introduced in a previous post. Here we will talk about how it incorporates feature selection. Remember that LASSO’s loss function has an extra term to penalize the weight of the model, apart from the usual mean squared error. The term is simply \(\lambda \mid \beta \mid\). It doesn’t just prevent the weights to become too large in absolute, it only can force some of the coefficients to be zero when \(\lambda\) is sufficiently large. In our example, the chosen variables are the ones with coefficients different from zero: the type of suite the client lives in, the education, the occupation, the day in the week that the client applies for the loan, and the organization type. One interesting variable is the week day that the client starts the loan process, it seems to be significant across feature selection algorithms.
from sklearn.linear_model import LassoCV
lasso = LassoCV(cv=5)
lasso.fit(X_train, y_train)
# To get the selected feature names
selected_features = [feature for feature, coef in zip(X_train.columns, lasso.coef_) if coef != 0]
print(selected_features)
['NAME_TYPE_SUITE', 'NAME_EDUCATION_TYPE', 'OCCUPATION_TYPE', 'WEEKDAY_APPR_PROCESS_START', 'ORGANIZATION_TYPE']
/Users/nguyenlinhchi/.local/lib/python3.9/site-packages/sklearn/linear_model/_coordinate_descent.py:1568: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
Elastic net
Since Elastic net is the mix between Lasso and Ridge, they also have that quality of selecting the relevant variables.
Decision tree and Random forest
A decision tree uses Gini or entropy impurity to estimate the quality of each split. Features at the top contribute to the final prediction more than others at the leaf. The expected fraction of the samples they contribute to thus can be used as an indicator of their importance. Random forest is also an algorithm that has the feature importance built in in sklearn library since it is an ensemble of decision trees.
from sklearn.ensemble import RandomForestRegressor
# Create a Random Forest Regressor
rf = RandomForestRegressor(n_estimators=100, random_state=42)
# Fit the model
rf.fit(X_train, y_train)
# Get feature importances
importances = rf.feature_importances_
# Convert feature importances to a DataFrame
importance_df = pd.DataFrame({
'Feature': X_train.columns,
'Importance': importances
})
# Sort DataFrame by the importance
importance_df = importance_df.sort_values(by='Importance', ascending=False)
print(importance_df)
Feature Importance
11 ORGANIZATION_TYPE 0.203309
10 WEEKDAY_APPR_PROCESS_START 0.148354
9 OCCUPATION_TYPE 0.118677
7 NAME_FAMILY_STATUS 0.090337
3 FLAG_OWN_REALTY 0.065496
14 WALLSMATERIAL_MODE 0.061458
2 FLAG_OWN_CAR 0.056228
5 NAME_INCOME_TYPE 0.052931
4 NAME_TYPE_SUITE 0.042914
1 CODE_GENDER 0.041188
6 NAME_EDUCATION_TYPE 0.038794
12 FONDKAPREMONT_MODE 0.031838
8 NAME_HOUSING_TYPE 0.025070
0 NAME_CONTRACT_TYPE 0.017171
15 EMERGENCYSTATE_MODE 0.005946
13 HOUSETYPE_MODE 0.000288
/var/folders/kf/5_ggvsz93vxdbx_h0tvy66xh0000gn/T/ipykernel_7037/1195280182.py:7: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples,), for example using ravel().
rf.fit(X_train, y_train)
The top four features are organization type, the week day that the process start (this one again, even though it seems that it should be an irrelevant feature before we run all the algorithms), the occupation of the client and the family status.
In conclusion, we have explored multiple ways to select the most relevant features for our model. If done right, there would be many benefits to enjoy from reducing the number of variables: better run time, more efficient computation, better accuracy even. Doing together with good data collecting and preprocessing practices, it would triple our performance. However, remember that which algorithm to take varies from dataset to dataset. And it is required that the person in charge has a sufficient body of knowledge on the matter.